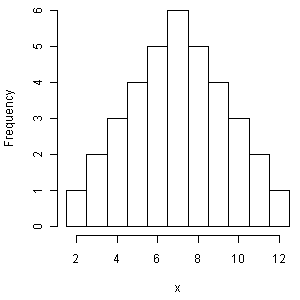首页
关于
论坛
R会
投稿
搜索
SAS
最近更新于2024-04-15
1 / 2
COS访谈
COS访谈第4期:谢梁(微软)
谢梁 / 谢益辉
/
2013-08-22
简介:谢梁,现微软(西雅图)高级数据科学家,在各大SAS论坛混迹的朋友也许不知道他的真名,但oloolo这个id可能大家都非常熟悉。本站小编谢益辉有幸在西雅图得遇谢梁真身:本家相逢,又是同行;把酒言欢,各自买单;幸甚至哉,采访即来。谢梁的个人技术博客。(因为现在不用SAS了,目前更新速度比较慢),更多信息,参见LinkedIn页面。 […] 我2000年从西南财经大学金融系毕业,毕……
统计软件
2012年SAS公司博客排名
高燕
/
2013-02-24
想要了解和学习 SAS 产品的同学,一定要看看这个博客排名,因为这里有你需要的绝大部分资料,从数据处理、图形显示、分析、培训到最新的技术和产品信息。 前10名: […] Rick Wicklin, 博士, SAS 公司计算统计学方面资深研发人员,PROC IML 和 SAS/IML Studio 的首席开发工程师。精通计算统计学、统计图形、现代统计分析方法,是 Statistical……
统计软件
关联规则:R与SAS的比较
高燕
/
2013-02-17
啤酒和尿布的故事是关联分析方法最经典的案例,而用于关联分析的Apriori算法更是十大数据挖掘算法之一(http://www.cs.uvm.edu/~icdm/algorithms/index.shtml,这个排名虽然是几年前的调查结果,但是其重要性仍可见一斑)。本文以《R and Data Mining》书中使用的泰坦尼克号人员的生存数据为例,介绍如何使用R和SAS的Apriori算法进行关联分……
统计软件
R与SAS的集成
高燕
/
2013-02-16
一位优秀的分析师不仅要有深厚的理论功底、丰富的实战经验,还要熟悉几款常用的分析软件,并有一款自己精通的软件。就像武林高手既有独门秘器,又要熟悉各门各派,这样才能博采众长,兼收并蓄,为己所用。 竞争促进创新,合作带来双赢。R与SAS各有优势,也各有问题,国内外网上骂战得多,思考如何将两者集成并能拿出可行方案的人则少之又少,即便有也基本都是老外或者外籍华人想出来的。这里不想贬低国人,只想建议大家多一些……
统计软件
Think SAS(二)
胡江堂
/
2010-12-30
有个老本家,著有《白话文学史》(上卷)、《中国哲学史大纲》(上卷),——你知道他叫胡适。然后有朋友问这个“Think SAS”系列有没有下文,我自然不敢托大,“半卷先生”不能做,还是老老实实地把这个系列往前推吧。 第一篇“Think SAS”中的“Think”,纯粹做“考虑”解,说,诸君如果为工作计,不妨考虑下SAS。下面说些关于SAS本身的一些思考与认识。俗话说,人类一思考,上帝就拍砖。上一篇……
统计模型
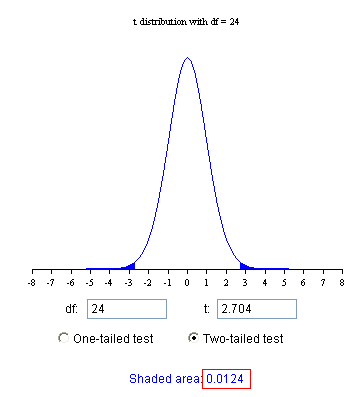
假设检验初步
胡江堂
/
2010-11-14
准备再尝试一下,用大白话叙述一遍统计推断中最基础的东西(假设检验、P值、……),算是把这段时间的阅读和思考做个梳理(东西不难,思考侧重在如何表述和展示)。这次打算用一种“迂回的”表达方式,比如,本文从我们的日常逻辑推理开始说起。 […] 复习一下普通逻辑的基本思路。假设以下陈述为真: […] 你打了某种疫苗P,就不会得某种流行病Q。 […] 我们把这个先决……
新闻动态
北京数据管理与生物统计论坛(BBF)第三次聚会见闻录
胡江堂
/
2010-09-05
9月4号下午,周六,去北大医学部参加了北京数据管理与生物统计论坛(Beijing Biometrics Forum, BBF)的第三次聚会,这次活动由SAS China和北京大学临床研究所赞助。这里写些会议见闻和一些零散的感想,不算是会议的正式“纪要”。东西贴这,大致想给“统计之都”(COS)的朋友交流下北京SAS技术社区的氛围、工作市场情况以及一些相关技术评论等等。 […] 西安杨……
统计模型
从中心极限定理的模拟到正态分布
谢益辉
/
2010-05-09
昨日翻看朱世武老师的《金融计算与建模》幻灯片(来源,幻灯片“13随机模拟基础”),其中提到了中心极限定理(Central Limit Theorem,下文简称CLT)及其SAS模拟实现。由于我一直觉得我们看到的大多数对CLT的模拟都有共同的误导性,因此在此撰文讲述我的观点,希望能说清楚CLT的真实面目,让读者对它有更深刻的理解。 […] 从广义的角度来讲,CLT说的是一些随机变量之……
统计软件
Think SAS(一)
胡江堂
/
2010-04-18
为什么你应该学SAS?本文不想卷入SAS与R,或者与SPSS、S-Plus、Matlab等统计软件孰优孰劣的争论中去,我是说,作为一个有志于投身工业界的统计分析人员,你为什么应该把SAS纳入你的分析工具箱?这会是一篇动员贴,尤其是对广大对数据分析感兴趣的在校生。在默认统计编程语言是R的“统计之都”,我需要拿上面这幅图来吸引眼球:学SAS吧。 R是好东西,不只是在COS,现在全世界的统计系和统计学……
推荐文章
我的求学之路:经济学、软件工程、SAS
胡江堂
/
2009-08-09
这个青年的经历,只代表他个人,没有任何群体的意义。 我想写下一段自白,这自白既是我个人的,也具有普遍意义,因为一个人经历过的事情所有的人都可以经历。 […] 跟武汉博文视点合作,召集些身边的朋友,2009应届生,计算机背景,在毕业之前,讲讲自己求学、实习、找工作等的经历与感悟,文章将由电子工业出版社结集出版,在今天秋季学期开学之前出来。我是主编,也是作者之一,刚好经历跟大伙有重叠:经……
机器学习
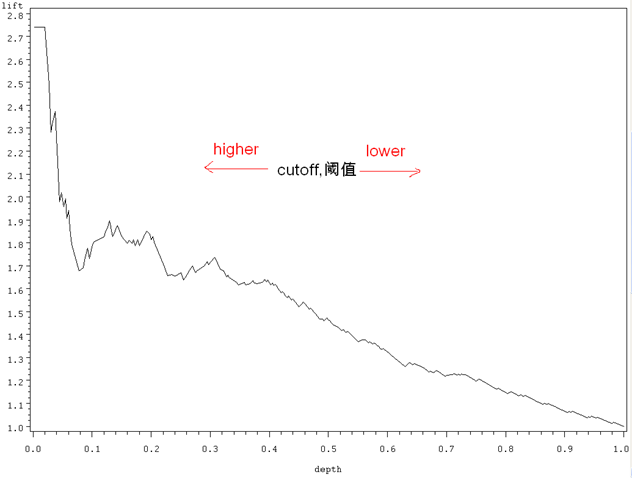
分类模型的性能评估——以SAS Logistic回归为例(3): Lift和Gain
胡江堂
/
2009-02-18
书接前文。跟ROC类似,Lift(提升)和Gain(增益)也一样能简单地从以前的Confusion Matrix以及Sensitivity、Specificity等信息中推导而来,也有跟一个baseline model的比较,然后也是很容易画出来,很容易解释。以下先修知识,包括所需的数据集: […] 说,混淆矩阵(Confusion Matrix)是我们永远值得信赖的朋友:……
统计软件
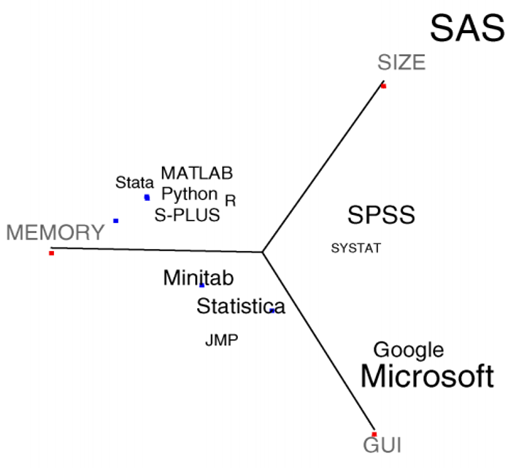
R与SAS之争:一个导读
胡江堂
/
2009-01-13
现在R与SAS社区里,最热闹的大概是源于《纽约时报》的一篇文章而引发的R与SAS之争。 2009年1月7号,《纽约时报》科技版登了一篇注定要引起四方瞩目的文章, Data Analysts Captivated by R’s Power(1月6号就有网络版),作者是该报的记者Ashlee Vance。这大概是开源统计软件包R,自1996年诞生以来,第一次出现在公众视野,而且是出现在《纽约时报》这样……
««
«
1
2
»
»»