首页
关于
论坛
R会
投稿
搜索
统计软件
最近更新于2024-04-15
1 / 5
统计计算
挑战最快 SVM!ReHLine 算法诞生记
邱怡轩
/
2023-12-22
本文由邱怡轩主笔,内容素材源自邱怡轩和戴奔共同讨论的结果。 […] 武林至尊,宝刀屠龙。长久以来,机器学习江湖中一直流传着两件神器——LibSVM 和 Liblinear,它们都是用来求解支持向量机(SVM)问题的,且都是由台湾大学的林智仁教授及其团队开发和维护。两者的不同在于,LibSVM 支持各类基于核函数的 SVM,而 Liblinear 只能计算线性 SVM。但从计算效率上来……
统计软件
DT 包速查手册
袁凡
/
2023-02-10
这是一份针对 R 中的表格包 DT 的速查手册。DT 包源自于 JavaScript(以下简称 JS) 中的 DataTables,但并非所有 DataTables 提供的功能都能在 DT 中实现,而 DT 中也有独立于 DataTables 之外的一些更贴合 R 语法的函数。 […] 本文使用的 DT 包版本为 0.27。 […] 全文共两个章节:……
R语言
龙芯可以做数据分析吗?
邱怡轩
/
2022-03-28
因为众所周知的原因,近几年来,计算机处理器芯片这个高科技产品受到了社会的广泛关注。一时间,一款名为“龙芯”的 CPU 好像突然成了“全村人的希望”,不管是业内大佬还是吃瓜群众,都开始对自研芯片这个话题展开了激烈的讨论。按照官方的说法,龙芯是我国首枚拥有自主知识产权的通用高性能微处理器芯片,最初在2001年是中科院计算所下属的一个课题项目,而到了2010年又成立了龙芯中科公司,从纯科研项目走向了商业……
统计软件
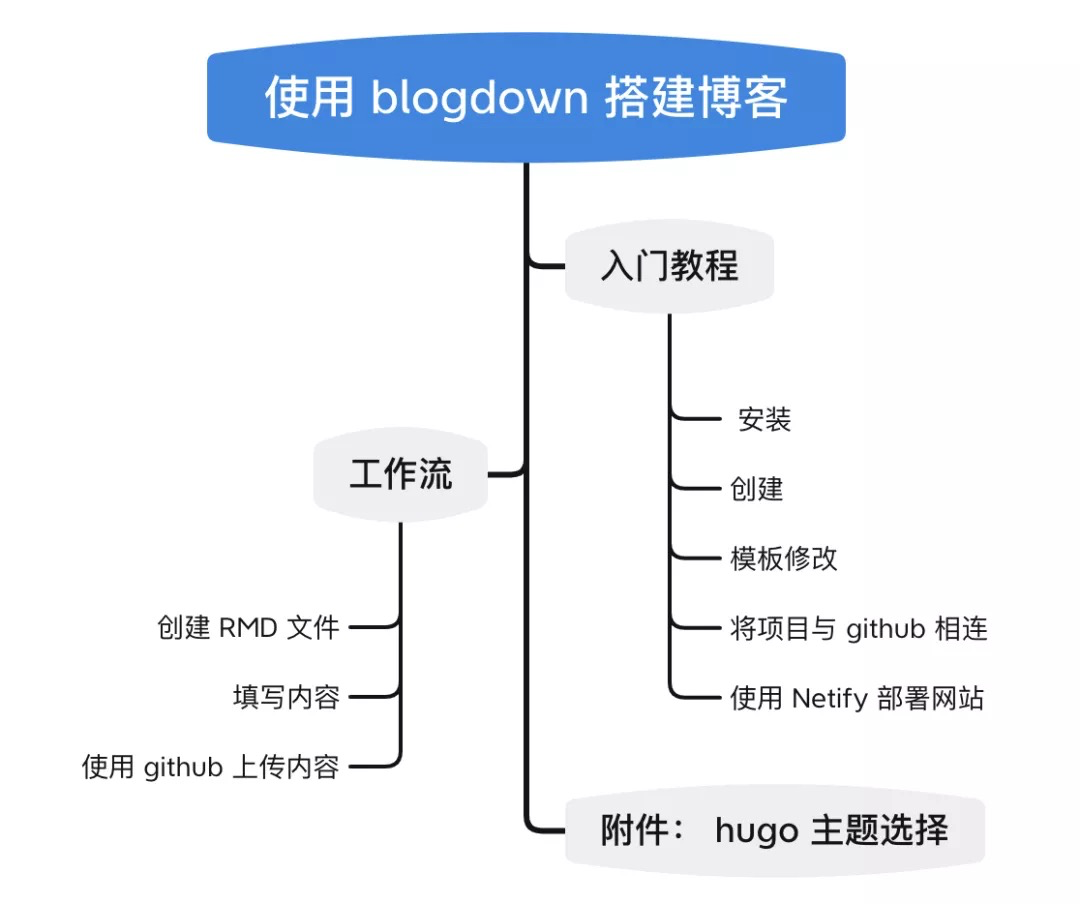
手把手带你搭建个人博客(基础版)
庄亮亮
/
2022-03-07
你是不是特别想创建一个自己的私人博客?使用 blogdown 搭建博客难度大不大?与其他方式搭建博客相比又有什么优点? 在使用过一段时间后,个人认为 blogdown 搭建博客的优势在于:它能将 R Markdown 与 Hugo 相结合,再加上 GitHub 和一个可以部署的网站,读者可以轻松的将一篇篇 Rmarkdown/markdown 的文章自动上传。而 R Markdown 的优势在于:……
统计软件
Tidyverse 优雅编程:从向量化、泛函式到数据思维
张敬信
/
2021-12-12
Tidyverse [1] 包是 Hadley Wickham 及团队的集大成之作,是专为数据科学而开发的一系列包的合集,基于整洁数据,提供了一致的底层设计哲学、一致的语法、一致的数据结构。 Tidyverse 用 “现代的”、“优雅的” 方式,以管道式、泛函式编程技术实现了数据科学的整个流程:数据导入、数据清洗、数据操作、数据可视化、数据建模、可重现与交互报告。 Tidyverse 操作数据的优……
统计软件
用R包gm生成音乐
毛任飞
/
2021-12-07
首先通过一个简单的例子来初步认识一下gm包。 这里有一段很简单的代码,它是用这个包写的。这段代码可以生成一段乐谱还有相应的音频。这段代码也可以直接在RMarkdown中工作,并且自动将生成的乐谱和音频嵌在生成的网页之中,音频可以直接播放。 这段代码非常简单,首先是加载R包,然后创造一个对象,最后将这个对象转化成音乐,我们现在来逐行看一下。 首先是Music这个命令,它会初始化一个Music对象,就……
统计软件
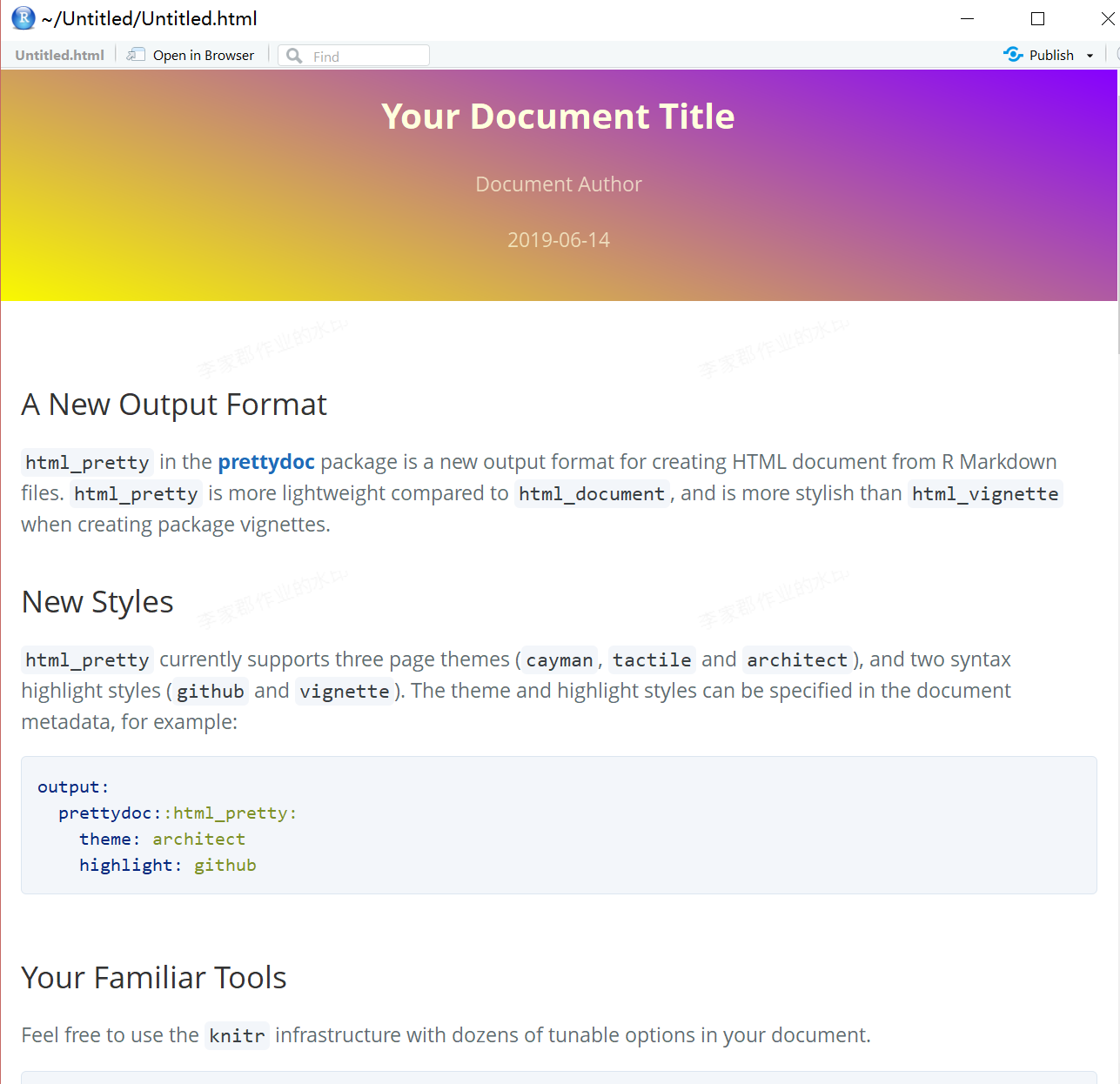
基于 Prettydoc 包的模板改造
李家郡
/
2019-10-05
在之前我的文章中,概括地介绍了修改 R Markdown模板的思路。本文希望基于一个创作 R Markdown文档的例子 (在电脑上看效果比较好),对常用的报告模板 Prettydoc 进行分析。读者可以根据自己的程度和需求,选择是停留在对模板的颜色、字体大小的程度,或是往前走一点——自己发明创造,进行阅读。 […] 其实自定义一份模板起初没什么特殊含义,但最近深感创作侵权违法成本太……
统计软件
基于 R Markdown 的演示文稿和报告模板使用经验
李家郡
/
2019-06-19
英语演讲课曾说,幻灯片只是辅助工具,而内容才是演讲的核心和本质。报告和幻灯片,其本质都是服务于“展示知识”这个过程,两者有着相通之处。利用 R Markdown 可以特别方便地将一份课程报告转化为课程答辩幻灯片,也可以将幻灯片填充些内容后形成总结报告。这四年来,利用两者的转换关系,我节约了不少时间。 作为排版困难者,我尝试着探索了一些只关注内容的幻灯片和报告的写法。随着四年统计学习,R 虽然已经快……
统计软件
gcForest算法原理及Python与R实现
徐静
/
2018-10-12
从目前来看深度学习大多建立在多层的神经网络基础上,即一些参数化的多层可微的非线性模块,这样就可以通过后向传播去训练,Zhi-Hua Zhou和Ji Feng在Deep Forest [1,2]论文中基于不可微的模块建立深度模块,这就是gcForest。 传统的深度学习有一定的弊端: […] 但是有一点是我们相信的,在处理更复杂的学习问题时,算法的学习模块应该要变的更深(论文The……
统计软件
电子表格中的数据整理
任怡萌
/
2018-07-28
本文翻译自Karl W. Broman和Kara H. Woo发表的Data organization in spreadsheets。作者Karl W. Broman,工作于威斯康星大学麦迪逊分校,担任生物统计和医学信息学部教授;作者Kara H. Woo,担任华盛顿大学信息学院信息管理员。本文已获得原作者授权。 […] 电子表格有着普通的矩形外表,但是它的使用存在数十年的争议。一……
统计软件
深入对比数据科学工具箱: SparkR vs Sparklyr
朱俊辉
/
2018-05-11
[…] SparkR 和 Sparklyr 是两个基于Spark的R语言接口,通过简单的语法深度集成到R语言生态中。SparkR 由 Spark 社区维护,通过源码级别更新SparkR的最新功能,最初从2016年夏天的1.5版本开始支持,从使用上非常像Spark Native。Sparklyr 由 RStudio 社区维护,通过深度集成 RStudio 的方式,提供更易于扩展和使用……
机器学习
为什么统计学家也应该学学 TensorFlow
邱怡轩
/
2017-08-22
(先啰嗦一句:本文的标题和内容牵涉到 TensorFlow,只是因为它是可用的工具之一,我相信很多其他的框架都可以做到文中我想要实现的功能。我自己并没有工具上的偏好,所以就当是拿 TensorFlow 举一个例子。) 对于学统计做统计的人来说,这可能是最好的时代,也可能是最坏的时代。好的地方我就不多说了,基本上关键词包括“大数据”、“数据科学”等,搜索引擎可以帮你列举出许多激动人心的字眼。为什么会……
««
«
1
2
3
4
5
»
»»