作者简介: 张云松,毕业于中科院,多年咨询公司和互联网公司从事数据算法、决策分析、风险管理和产品设计的工作,目前是融360风控总监,负责纯线上小额微贷信用贷款产品。

最近几年,这波在资本撬动的互联网金融的浪潮极大地提升了数据科学的行业应用价值,数据分析师不再是苦逼的跑数的,摇身一变成了风控模型专家、数据科学家。 尤其是大数据风控、大数据征信领域一片火热的场景,数据挖掘、机器学习相关专业同学的数量也翻番上涨,越来越多的计算机和统计领域的同学加入互联网金融行业。

面试中发现很多同学的梦想工作都是我要做机器学习相关工作、我要做算法、我要做模型…… 但其实以一个互联网金融从业者角度看,我们大量的时间还是在做数据理解、数据处理、重复验证特征、不停的在做实验,我 对模型师的定义基本就是半个蓝领,只不过很多学术和一些五花八门的算法和方法可以真正有机会应用到商业领域并且产生价值。
本文分享一些互联网金融从业者日常工作中实际用到的与数据科学相关的内容,由于日常工作中涉及到的数据和策略非常敏感,本文中不会透露具体产品策略, 只会对一些思考和方法进行介绍;同时,由于如今互联网金融产品的形态非常多,下文主要介绍目前很热的在线授信贷款产品中数据科学的应用。

在线授信贷款产品也是互联网金融产品中路径最长,最复杂的产品,类似产品形态为蚂蚁借呗、京东白条、各种手机上的贷款app。 在线授信产品有别于传统个人信贷产品,用户不用提交一堆纸质材料,也不用上门面签,也不用等几天甚至十几天才能知道审批结果,用户只需要在手机app或微信上完成贷款申请,十几分钟甚至几分钟就能获得贷款额度,很快就能放款成功,极致的互联网贷款体验。 用户完整申请流程如下,整个过程完全线上化,只要你有一台智能手机即可尽享便捷。
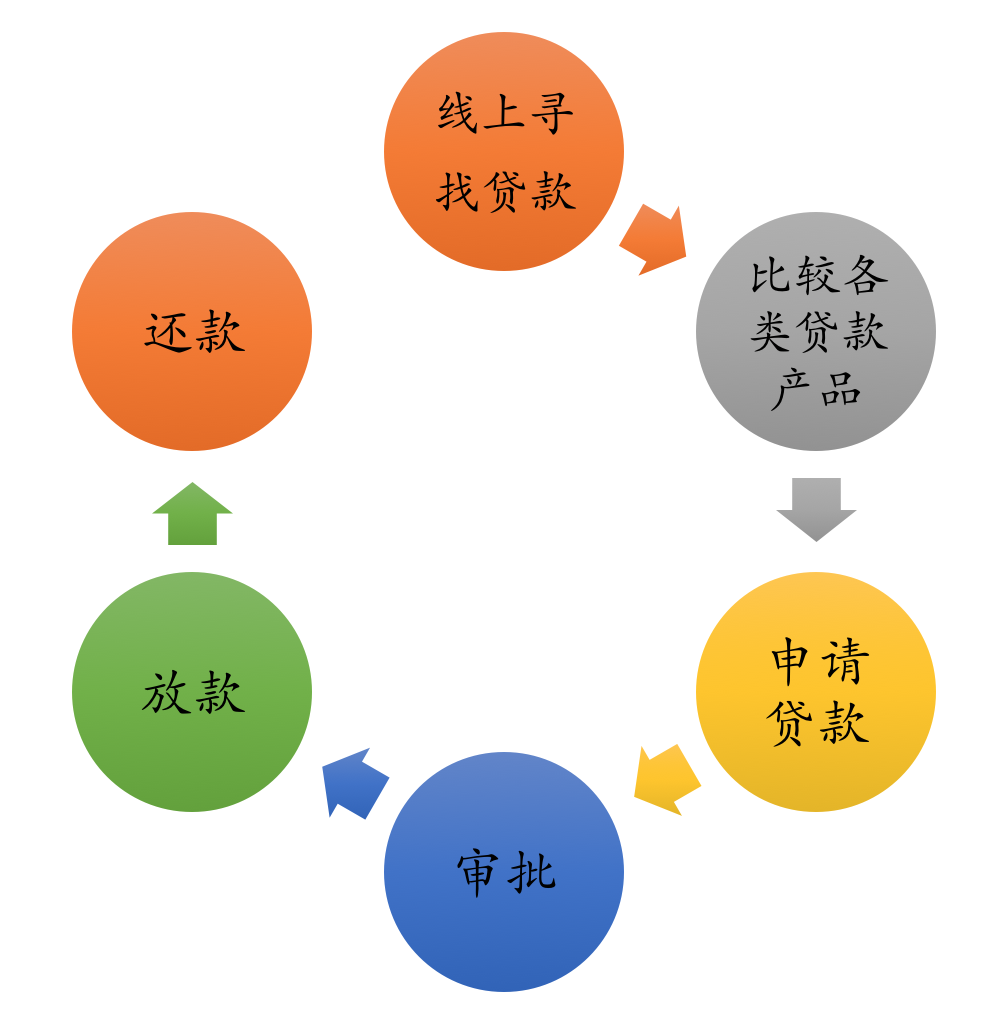
用户申请贷款流程
一、转化率
所有互联网产品基本都离不开转化率,互联网用户流量都是买来的,能形成转化有变现能力的产品才有竞争力。 对于在线贷款行业,转化率是一系列 growth hacking 的黑科技中更有挑战的问题。 因为贷款类产品的转化率不止和用户漏斗的页面转化有关,还和风控产品的政策有关。 前面再高的转化率如果吸引来的都是高风险用户那也无法提高审批通过率。最终转化率优化的目标是为了整体流量购买带来的收益最高,即优化流量投放 ROI。
为实现流量购买的 ROI 最高就需要通过数据化决策计算出流量定价,对每个流量提前预测出放款后带来的整体收益。 举个例子,我们经常通过一些效果类的投放进行流量购买,比如百度 sem、腾讯的广点通,都可以通过优化搜索词或用户标签的方式进行流量优化。 流量优化过程中百度和广点通会根据我们提供的关键词进行精准引流。 我们通过风控模型中显著的用户画像特征来辅助优化流量投放关键词,结合转化率漏斗和计算用户群的盈利能力进行精准的流量投放定价,数据化决策充分用到了流量购买,其中预测模型也作为一个基础基石用于决策流程, 比如用户意愿预测模型、用户收益预测模型。整个数据流在业务决策中的打通有效提高我们产品整体的转化率。 曾经我们发现一个乌龙,风控制定的一个贷款风控审批中的禁贷人群,其关键词居然被市场投放人员用于投放广告词! 通过这种方式我们可以实现了两个月内投放成本下降到初始的三分之一。
二、反欺诈

在线贷款行业是一个大蛋糕,尤其对骗子来说,不管是线下的贷款中介代办包装还是线上的盗号刷单等黑产从业者,都盯上了在线贷款。 反欺诈能否做好是在线贷款行业的一条生死线。简单普及下欺诈模式,可以分为一方欺诈和三方欺诈:一方欺诈通常指骗子来申请贷款后没有还款意愿造成违约,三方欺诈指欺诈分子借用冒用他人身份或协助他人伪造申请信息进行骗贷。下 面重点介绍下数据科学在识别三方欺诈中的一个应用:社交网络分析用于识别组团进件。
我们存在一个基本的假设,骗子的朋友是骗子的概率更大,正常还款的用户的朋友正常还款的概率大,并且我们要对不良的贷款中介要进行识别。 因为中介骗子会帮很多还款意愿不强的人通过提供虚假、伪造、包装申请信息的方式进行骗贷,同时还会教申请人如何应对。 通过中介(或者本身就是团伙)进行集中贷款申请的风险非常高,是一种常见的欺诈类型,分析发现社交网络分析和其他交叉检验方法能有效识别上述欺诈模式。
我们定义用户和用户之间如果共用某些核心信息,那么他们之间就存在紧密联系,这些核心信息可以是手机设备、电话号码、身份证、银行卡号、邮箱等。 以这些信息作为点,信息之间的关系作为边就可以构造出类似下面的图网络。
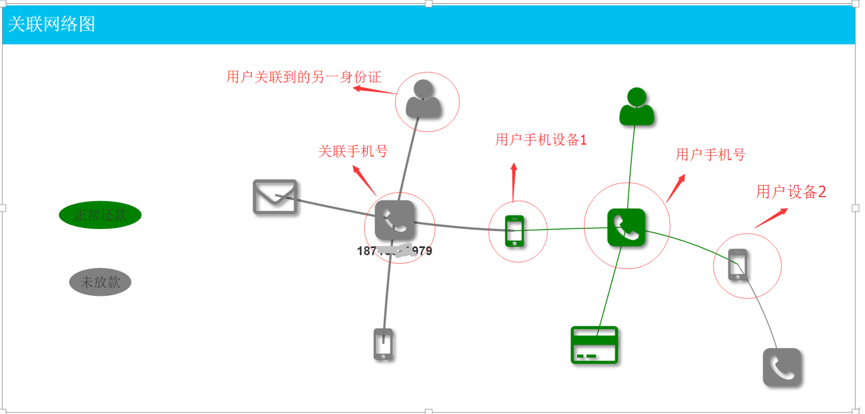
如上图,图中有两个用户通过手机申请贷款,一个放款成功,一个放款失败,通过用户申请中提供的信息,将其核心信息构建成一个网络图,可以看到两个用户一共关联到3个手机号,3部手机设备,两个用户是通过一个公用的手机设备联系起来的。 上图的真实业务场景是尾号979的用户来申请时,发现与其强相关的用户已经成功放款,并且通过图上的关系已经申请调查出尾号979的用户是之前放款用户的配偶,若批准尾号979的贷款申请则将增加两人整体负债,所以最终审判拒绝掉了这笔贷款申请。
上面是一个简单例子,真实业务中欺诈与反欺诈是道高一尺魔高一丈的博弈过程,简单的反欺诈策略很容易被真正的欺诈分子发现并规避,简单策略的效果会不断下降。 事实上欺诈很难被完全解决,反欺诈的一个重要思路就是不断的提高欺诈分子作弊的成本,并且保证策略准确性情况下使反欺诈策略更智能并且更复杂。
这种思路下同样是通过社交网络反欺诈,我们需要更全面的描述每个用户之间的关系,用户之间关系的定义也不止是上述这些强关系,还包括很多弱关系,比如用户间打过电话,用户间是同一单位,用户家庭住址在同一区域,用户之前是 QQ 好友等,这些更多的关系关系的叠加很容易出现下面类似的用户间非常复杂的关联网络。
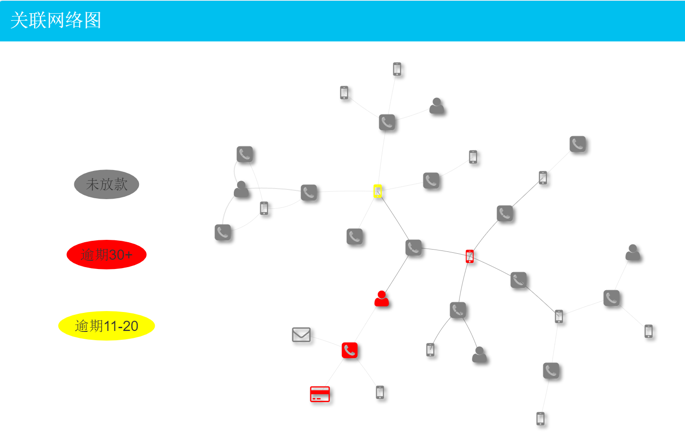
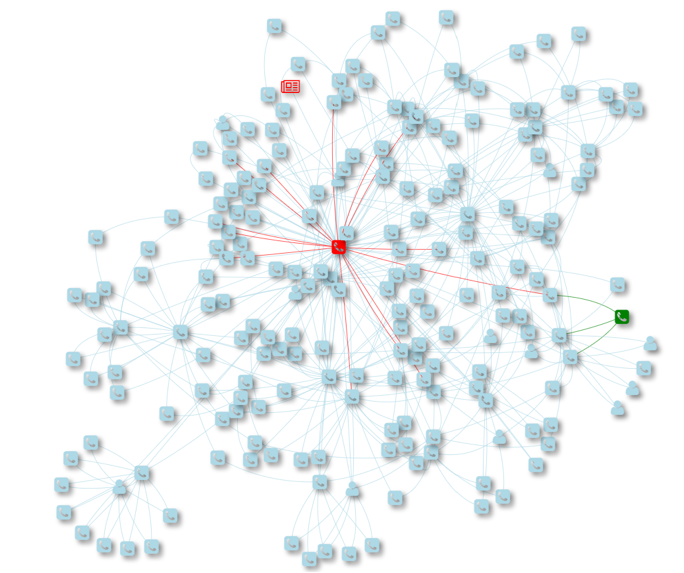
构建图的同时,对每个点还可以赋予不同的属性,这些属性可以用于后续的特征工程提取。 举个例子,对图中用户身份证类型的顶点,可以设置多个属性,如是否黑名单、用户资产、是否有房。 后续特征工程中就可以根据顶点属性衍生出具体的特征,如一度关联的身份证是黑名单的顶点个数。 用户关系网络图构建的最终目的是提升欺诈团伙的识别准确度以及实现自动化的反欺诈决策,即提升欺诈识别的效果和效率。 我们希望通过社交网络挖掘出用户更多的特征用于反欺诈模型和策略的训练, 所以对于这种复杂的用户关系网络图,接下来我们要进行两件事,其一,用户图特征提取;其二,点属性标签的补全。
-
用户特征提取

每个用户都可以通过手机、身份证等关键信息点,获取单个用户网络的连通图(事实上对10亿级节点的图的查询效率已经非常低了,在实时决策的场景下需要通过算法优化来解决响应时间的问题,比如图入库的锁问题,异常点的查询超时)。对每个点计算其在图中常用的属性特征,比如度、接近中心度、page rank 中心度、betweenness 中心度。这个过程可以看作是对给定用户,通过图数据进行特征工程。大部分策略和模型的效果往往由特征工程的质量决定,甚至特征工程方法也成了各家公司不可泄露的核心内容,数据算法工程师的苦逼日子也由此开始……举几个例子,除了上面简单的点中心度相关的直接特征还能直接想到非常多的特征,比如用户 n 度关联点的关联手机号数、用户关联到的设备号占所有关联点的比例、用户关联的黑名单身份证号数等等。细心的同学可以看出上述举例的特征计算大部分可以实现标准化,通过开发单独特征工程模型实现上万特征的衍生计算。这样能极大提升模型开发的效率,后文单独介绍下我们的一些经验。
-
点属性标签的补全
在策略分析和特征计算中,我们需要很多点的标签属性,比如对某一身份证是否是黑名单,身份证是否有房,身份证是否信用卡额度超过3万等等。但是实际上往往对于大部分用户标签属性是缺失的,比如用户申请到一半就流失了,用户最终放弃了,我们都没法准确收集这些标签。怎么办?我们通过图相关的社群发现算法进行标签补全,比如最常用标签传播算法 LPA(Lable PropagationAlgorithm),还有类似的算法,比如 SLPA、HANP、DCLP等等。
虽然通过尝试算法可以快速补全标签属性,但很快我们就发现补全后的效果不一定理想。其中有两个业务产生的数据问题。其一,噪音数据造成很多奇异点使非相关的用户关联到一起,造成数据失真。一个常用的场景就是很多用户都会拨打10086,很多人都会被同一400的骚扰电话骚扰,那么这些现实生活中本没有关联的用户被关联到一起;其二,由于用户的贷款是较独立的事情,所以每个用户的图规模较小,没有足够的已标记数据对其进行标签传播,造成最终标签传播的覆盖率降低,类似下图中的情况。

对第一个问题可以通过数据清洗部分解决,但需要大量的人工标注,成本很高;对于第二个问题现在也没有非常好的方案,欢迎社交网络分析的高手给出建议。
三、策略模型
在线贷款产品的核心竞争力就是数据化决策的效果和效率,整个业务中模型应用非常普遍,基本上在整个用户生命周期中都可以体现并发挥价值。如下图:
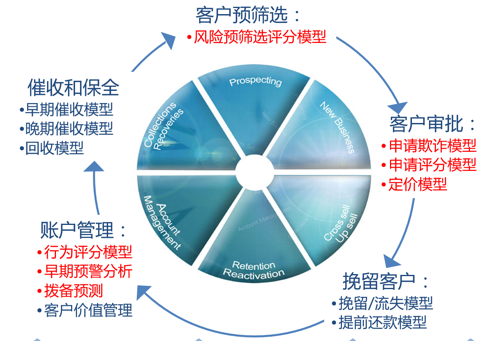
由于近两年大数据和互联网金融非常火热,对于风控模型的普及和介绍随便搜一下就有足够多的科普和介绍。我还是从一个从业者角度分析下模型开发中最关心的几个问题,来看如何应对业务场景造成的模型挑战?
-
业务初期如何解决冷启动问题?
业务上线前没有信贷表现样本,所以授信决策通常由信贷专家的经验决定。但如果一直依赖人工判断,人为判断的不确定性和人工依赖将严重影响业务的扩展,也无法通过互联网快速复制扩展业务,所以我们希望在业务初期能将人为经验进行一定量化总结,业内常用层次分析法(AHP)这种定性加定量的方式建立风控评分。层次分析法通过将人工授信决策的复杂思考抽象成一个个两两决策比较,最终将授信决策形成一个量化的评分表。在传统信贷产品中 AHP 方法在业务初期很长一段时间并不比定量模型差很多。
-
业务中期如何处理样本的不平衡问题?
在业务发现中期,有了一定放款用户作为模型训练的样本,使用违约用户作为模型的正样本,但对于信贷业务中违约率都在5%以下,面临数据挖掘中常见的不平衡样本(imbalance)问题,通常可以用过采样(oversampling)或欠采样(undersampling)处理样本。
具体而言,即对违约样本进行重抽样,或从非违约样本中进行抽样。但在信贷业务中,不止正负比例问题,还有由于总放款量不足,违约样本过少的问题。过采样的方法在这种情况下对模型效果的提升还是非常有限(除了 bootstrap 的采样方法还可以尝试 SMOTE 进行采样,不过我实际工作中尝试在信贷风控模型中 SMOTE,发现其表现并不稳定),这种情况经常被称作低违约资产组合(LowDefaultPortfolio,LDP)。还有一些其他的处理非平衡数据的思路可以尝试,比如通过某种方法增加正样本,在金融领域可以通过经验丰富的信贷专家对拒绝用户进行人工标注加入模型正样本,或通过用户信息相似度聚类方法对表现期不充分的用户进行标签重置;比如被信贷专家拒绝的申请虽然没法完全证明放款后一定会违约,但其风险通常比被信贷专家通过的高很多,在建模中可以把这些拒绝 case放入模型……另外也可以在损失函数定义中对正负样本赋予不同的权重,在真正业务中很少采用,基本信贷领域的模型还是依赖特征来增强模型效果。虽然这些方法的真实效果不如真实用违约样本进行建模效果好,但在细节模型调优中都是常用的尝试方法。
-
如何做一个优质的特征工程?
特征工程做的好坏是所有模型师保持饭碗的有效手段。在线授信领域对特征的挑剔更上一层,由于大部分预测模型都是用历史几个月前的数据去预测未来几个月或1年发生的违约事件,所以对特征的效果、特征稳定性、可解释性中需要不断平衡。每个模型都需要做大量的数据特征处理,为了提升效率最好把常用类型的数据的特征工程开发成包。举个特征工程的例子:
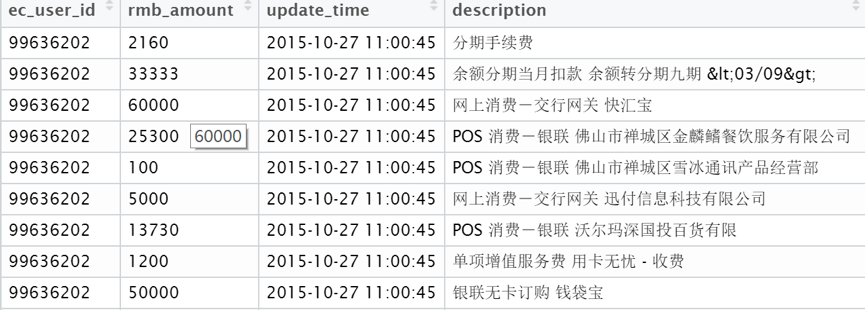
上图中是用户提供的信用卡消费账单数据,其中包括用户id、交易金额、交易时间、交易描述。上述只有4个字段的用户数据如何进行特征工程?可以从如下几方面入手考虑:
-
RFM模型
对于有用户重复交易的数据,RFM是最有效的特征衍生方法。通过 recency,frequency, monetary 三个维度衍生出非常多的特征,比如最近1周交易金额次数、最近3个月交易金额平均值等等特征。
-
文本分类
上述交易描述(description)字段中是非结构化的文本,每笔交易可以被赋予一个或多个标签分类,比如通过交易描述中的内容,可以将交易分类为分期交易、取现交易、消费交易。通过交易描述可以产出不止一类的分类体系,比如还可以将交易分成线上交易(支付宝、财付通等)、汽车交易、生活消费交易等等。对每个分类通过上述RFM生成的特征都可以再衍生一层特征,比如最近1周取现交易次数、最近3个月线上交易平均值等。
对交易描述进行的文本分类可以做得很深(LDA, Naïve Bayesian),也可以通过分词后的统计分析的方法给出非常实用的分类。无论采用哪种文本分类方法,关键在于这类基础标签的效果如何评估。由于我们最终需要用这些分类标签用于分析用户的违约概率,所以我们可以采用一些先验的方法,使分类标签可以对用户违约风险有比较显著的区分力。在实际业务中优化文本分类产生的特征能非常有效的提升,这点很容易理解,文本中挖掘的特征其实是用户真实行为习惯的描述,一旦数据足够充分这种方法衍生的特征就是在刻画一个自然人的金融及生活模式。财务数据是风险预测最有效的维度之一。
-
时间序列
RFM 模型中通常只对交易金额进行简单的算术和统计计算,事实上对用户每个用户按时间排序的交易数据,可以看做是一个时间序列。对于交易金额组成的一个时间序列,我们抽取每个用户组成的时间序列中季节性系数、白噪声、时间序列中自回归模型的模型系数,这些值都可以认为是描述一个用户金融行为的特征!
由于互联网金融业务场景中获取用户强相关的数据相对有限,对于建模来说很多时间就是在不断的无脑挖特征,验证特征,再重复……
-
参考文献
SMOTE:https://www3.nd.edu/~nchawla/papers/ECML03.pdf
后记
多年来一直受惠于统计之都的精华文章,并从与各位有情怀的大神的交流中收益匪浅,但无奈水平有限又陷于俗事一直没时间总结下实际工作中用到的数据方法,这次受雪宁之邀撰文也是仓促中摘了些工作中零散的点,不算成体系。平常总是嘴炮居多,一落到纸上发现细节繁杂,总结不足。文中可能涉及一些业务内容,抱歉于篇幅原因不再做备注。
从事数据相关行业十余年来,看到其实数据科学真正能在工业领域充分发挥决定性作用的时候少之又少,多少数据昏析师迷茫于此,找到一份数据化决策能发挥极大价值的职位,能承载一个数据小兵到数据科学家的行业是每位数据从业人员的幸运。大家共勉!
关于作者
张云松毕业于中科院,多年咨询公司和互联网公司从事数据算法、决策分析、风险管理和产品设计的工作,目前是融360风控总监,负责纯线上小额微贷信用贷款产品。 |  |
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:editor@cos.name),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

发表/查看评论