首页
关于
论坛
R会
投稿
搜索
统计之都
最近更新于2024-04-15
2 / 52
推荐文章
统计月读(2022 年 11-12 月)
2023-01-01
推荐语:shiny 现在有 Python 版本了,这是一篇 Python 中使用 shiny 的教程 推荐人:孔令仁 链接:https://appsilon.com/shiny-for-python-introduction/ […] 推荐语:和机器人聊聊天活就干了。 推荐人:任焱 链接:https://github.com/isinaltinkaya/gptchatteR……
COS访谈
统计之都访谈第46期:数据科学先驱John Tukey
2022-12-05
编辑部按:统计之都访谈第46期为翻译作品。原文作者是Luisa T. Fernholz 和 Stephan Morgenthaler,标题为 A Conversation with John W. Tukey and Elizabeth Tukey,于2000年发表在Statistical Science。译者:陈星宇(华中科技大学数学与统计学院19级数学与应用数学专业在读学生)、徐泓、蔡再利,审……
推荐文章
统计月读(2022 年 10 月)
2022-11-01
推荐语: “How to do statistical research" 包含了一些对统计科研新手的有益建议。更重要的是推荐这个ASA做的网站,虽然近年的更新不多,但是沉淀着不少有意思的文章! 推荐人:陈格平 链接:https://stattrak.amstat.org/2013/06/01/how-to-do-statistical-research/ […] 推荐语:……
推荐文章
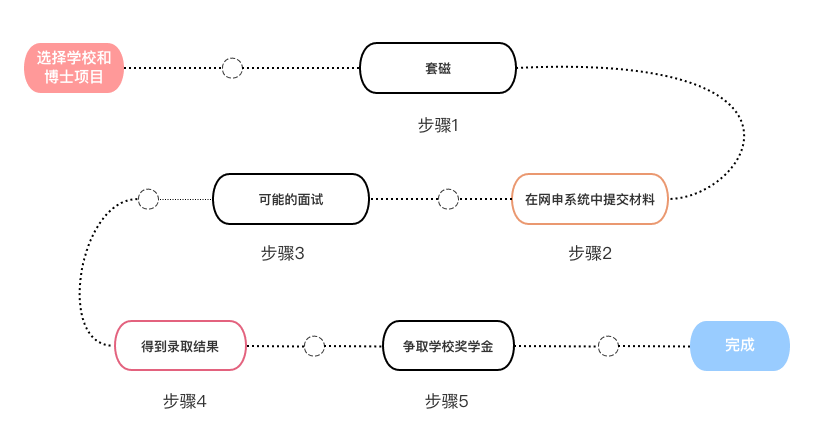
北美博士项目申请经验
张沥今
/
2022-10-28
我申请的是2022 Fall计量心理学/教育测量方向,拿到了以下offer:Notre Dame, Stanford, UW-Madison, UNC-Chapel Hill, UCLA, UC Davis。写这篇攻略的初衷是因为在申请中收获了太多无私的帮助,希望能将我得到的帮助传递下去。 下文略去了我自己的申请细节,旨在总结出更普适的规律,包括: […] 攻略中提到的文件都放在了这……
推荐文章
因果推断的统计方法
苗旺 / 刘春辰 / 耿直
/
2022-10-27
本文出自《中国科学:数学》2018年12期上同名文章,获得作者授权后转载。 […] \[ \def\ind{{\perp\!\!\!\perp}} \def\nind{{\not\!\perp\!\!\!\perp}} \] […] 探求事物之间的因果关系是哲学、自然科学和社会科学等众多研究所追求的终极目标。古希腊哲学家德谟克利特(约公元前400年)认为:发现一个因果关……
COS访谈
统计之都访谈第44期:统计遗传学之路——西湖大学杨剑老师
2022-10-24
杨剑,西湖大学生命科学学院教授,2003年本科毕业于浙江大学,2008年于浙大取得博士学位,同年赴澳大利亚昆士兰医学研究所从事博士后研究工作。2012年加入澳大利亚昆士兰大学,历任研究员、高级研究员、副教授、教授(2017)。2020年9月加入西湖大学生命科学学院。曾获得澳大利亚百年学院劳伦斯创新奖(2012),澳大利亚科学院Ruth Stephens Gani人类遗传学奖章(2015),澳大利亚……
推荐文章
统计月读(2022 年 9 月)
2022-10-01
推荐语:这个Repo存储了一个Julia用户群体关于写好清洁科研代码的互助与讨论活动记录,适合对Julia感兴趣,或者对于这种活动形式感兴趣的人。 推荐人:孔令仁 链接:https://github.com/JuliaDynamics/GoodScientificCodeWorkshop […] 推荐语:生成Rainbow Table很多已经闭源,如果有候选范围,想生成特定用途的精简……
推荐文章
我的三次美国博士申请
郝鸿涛
/
2022-09-21
上高二的时候,在家里自学,有一天晚上不知道怎么冒出的想法,想去美国留学。现在想想很可笑。我家里没钱,在国内上大学都算是一个不小的负担了,怎么可能去美国上大学呢。不过,这可以算是我第一次动起去美国留学的念头。 我大学学的是英语专业,反而没有多少出国的念头。到了大三第二个学期,一直想去美国的加州整合学院读心理学研究生,虽然我十分清楚那个学校不可能有奖学金。2014 年底,寒假在老家,第一次报名托福的时……
推荐文章
统计月读(2022 年 8 月)
2022-09-01
推荐语: 关于贝叶斯统计的一门课程,有配套书籍和公开课视频(B站搜名称有搬运),数理内容比较少,侧重代码实战(官方R+stan,也有 Python 和 Julia 版)。 推荐人:孔令仁 链接:https://xcelab.net/rm/statistical-rethinking/ […] 推荐语: 2 小时 workshop 几乎零基础学习 Quarto,一个开源的科学和技术出版……
推荐文章
Erich L. Lehmann :一份传记备忘录
P. J. Bickel / K. A. Doksum
/
2022-08-17
统计学起源于物理学、生物学和社会科学的许多学科的汇合。粗略地说,它可以被认为是使用概率模型和随机变化的度量分析数据的理论和实践。统计学中出现的著名名字包括 Bernoulli, Laplace, Gauss, Boltzman, Mendel, Quetelet 和其他许多人。现代数理统计理论的基础主要是在二十世纪由 R. A. Fisher , J. Neyman 和 A. Wald 奠定的。这……
R语言
R Markdown 制作 beamer 幻灯片
黄湘云
/
2022-08-14
LaTeX 提供 beamer 文类主要用于学术报告,从面上来看,好多主题是大学开发的,大家不约而同地使用蓝调,看多了想睡觉。目前,现代风格的 beamer 主题已经陆续涌现出来,本文旨在介绍一条 R Markdown 制作 beamer 幻灯片的入坑路径,让 beamer 看起来更加清爽些!
推荐文章
统计月读(2022 年 7 月)
2022-08-01
推荐语:可以称得上划时代的几何学教学技术,通过网页实现交互式高亮,随着阅读流程一同标记文本和对于绘图的内容,把几何原本做成了一本网页上可以动态看的教科书。另外提醒一下,网页配色有黑白两种模式,切换在右上角。 推荐人:孔令仁 链接:https://elements.canberead.com/ […] 推荐语:Bin Yu 老师在ICM 2022上的最新报告 Interpreting……
««
«
1
2
3
4
5
»
»»